The following image demonstrates the final workflow that is carried out, with some abstractions and simplifications, but still extremely simple.
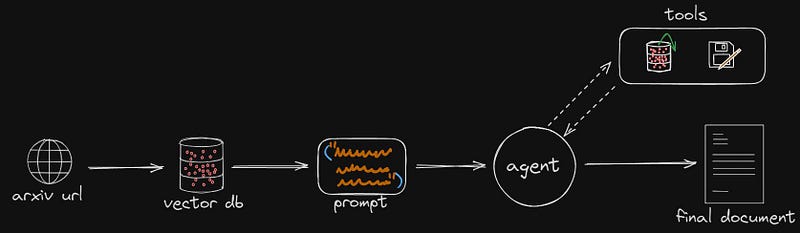
Data collection, preprocessing and storage:
We start with the usual steps: PDF parser, text preprocessing and generation of embeddings to create a vector database that stores the content of the PDF.
With the vector database ready, the important explanation comes, Agent:
The agent is the core of everything. It is composed of an initial prompt that instructs its behavior (although in the workflow I presented it as a step earlier and it is not part of the agent.), a large language model or LLM (I used GPT but LLaMa 70B should perform well), and additional tools.
Tools:
In this case, the most relevant tool is the retriever of the vector database, which will allow querying the PDF.
How is this achieved? Through a chain formed by the retriever of the vector database, a prompt for RAG, the LLM, a schema for the output format and the query itself. Once this chain is created, with simple queries coherent and well-formulated responses can be obtained from the vector database, not just the knn of the query.
Agent’s internal workflow:
Going back to the agent itself, unlike chains where the sequence of actions is hardcoded, in agents the LLM ‘reasons’ and determines what actions to take and in what order.
Basically, the agent chooses the sequence of actions as it obtains results and iterates until it fulfills what is requested. Unlike a simple LLM that responds in seconds, this gives it the ability to ‘orchestrate’ and break down its own workflow.

Output:
Here is an example of the agent’s analysis of two papers.
Attention is all you need (full text clicking here):

Extending Llama-3’s Context Ten-Fold Overnight (full text clicking here):

It should be noted that since it is a single agent performing a simple task, more complex concepts such as nodes, state, conditional edges or graphs, which are related to multi-agent systems, do not come into play.
Thanks everyone for reading ❤.