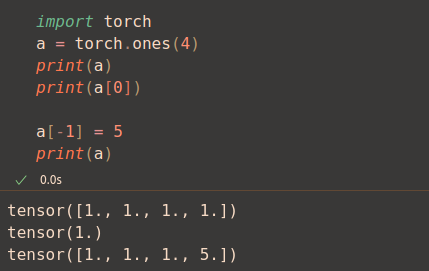
This is how Tensors, a way to store and handle data, looks like in PyTorch, in this case is just a row (1-dim tensor):
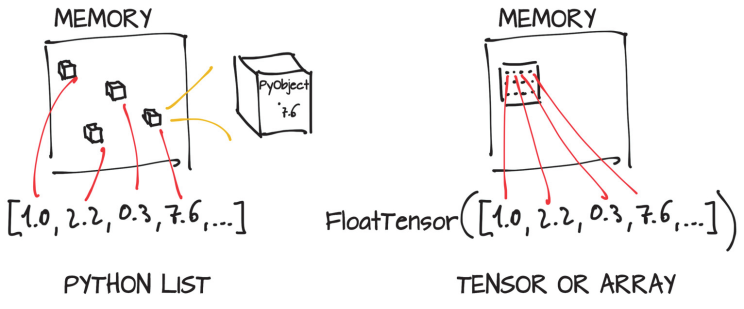
Python lists are collections of objects which are individually allocated in a container of memory, on the other hand Torch Tensors (and Numpy arrays) are views stored in a contiguos memory blocks who contains C numeric types.
But let’s see how much memory it implies directly in the code:
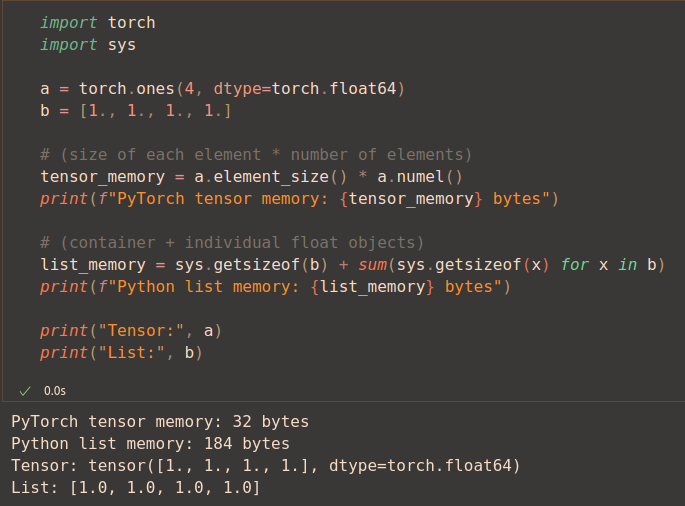
Why is this happening?
Python List stores (184 bytes):
- list object itself (with metadata, reference count, type information).
- each value is an object (with header, reference count, type pointer and the actual float64 value).
Torch Tensor stores (32 bytes):
- raw data only, so is 8 bytes each float64.
What is PyTorch doing? store the values sequentially, managed by `torch.Storage`.
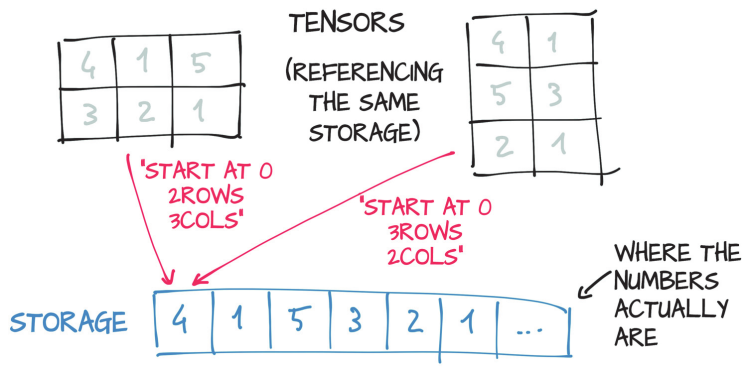
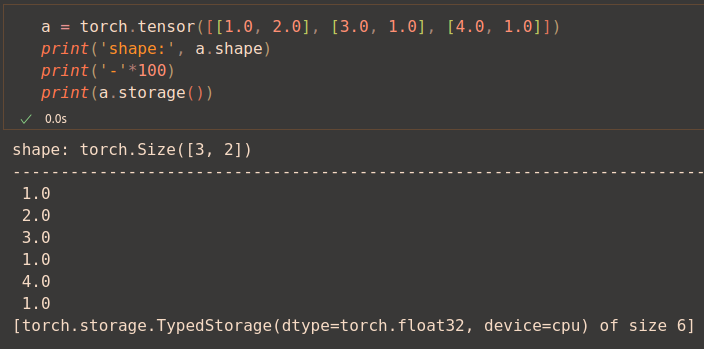
A Storage is a one-dimensional array of numbers, so a Tensor is basically a view of a given storage, formatted to fit the required structure.
You can see in the image that multiple tensors can index in the same storage, even with different indexes. The memory is allocated only once, and each tensor is a different view of the storage.
The following code example show it: a 3x2 tensor, stored in sequentially in one dimension of size 6.
Thank you for reading :)